Topological Semantic Graph Memory for Image-Goal Navigation
Nuri Kim Obin Kwon Hwiyeon Yoo Yunho Choi Jeongho Park Songhwai Oh
Robot Learning Laboratory in Seoul National University
Published at CoRL 2022 (oral)
Paper | Code | Project Page | Slides | Other Projects
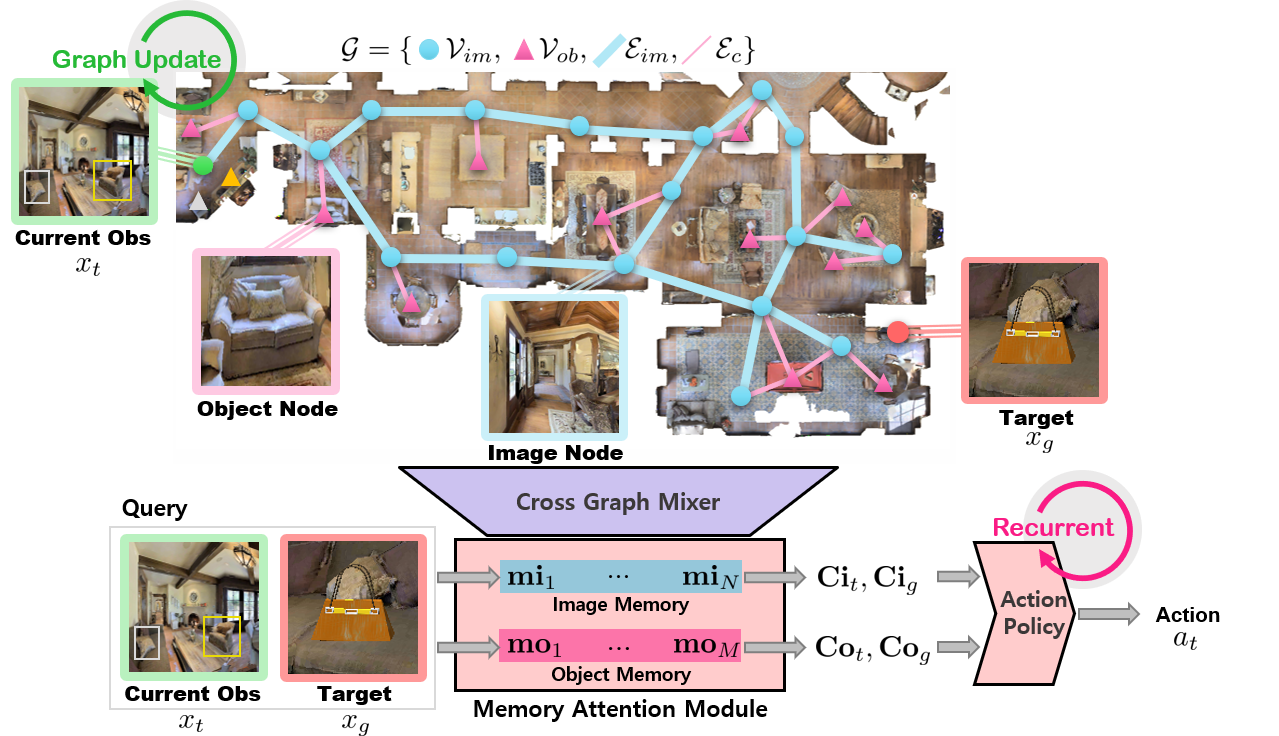
This work proposes an approach to incrementally collect a landmark-based semantic graph memory and use the
collected memory for image goal navigation.
Given a target image to search, an embodied robot utilizes the semantic memory to find the target in an unknown
environment.
We present a method for incorporating object graphs into topological graphs, called
Topological Semantic Graph Memory (TSGM).
Although TSGM does not use position information, it can estimate 3D spatial topological information about objects.
TSGM consists of
(1) Graph builder that takes the observed RGB-D image to construct
a topological semantic graph.
(2) Cross graph mixer that takes the collected memory to
get contextual information.
(3) Memory decoder that takes the contextual memory as an
input to find an action to the target.
On the task of an image goal navigation, TSGM significantly outperforms competitive baselines by +5.0-9.0% on
the success rate and +7.0-23.5% on SPL, which means that the TSGM finds efficient paths.
Why an agent needs a topological semantic memory?
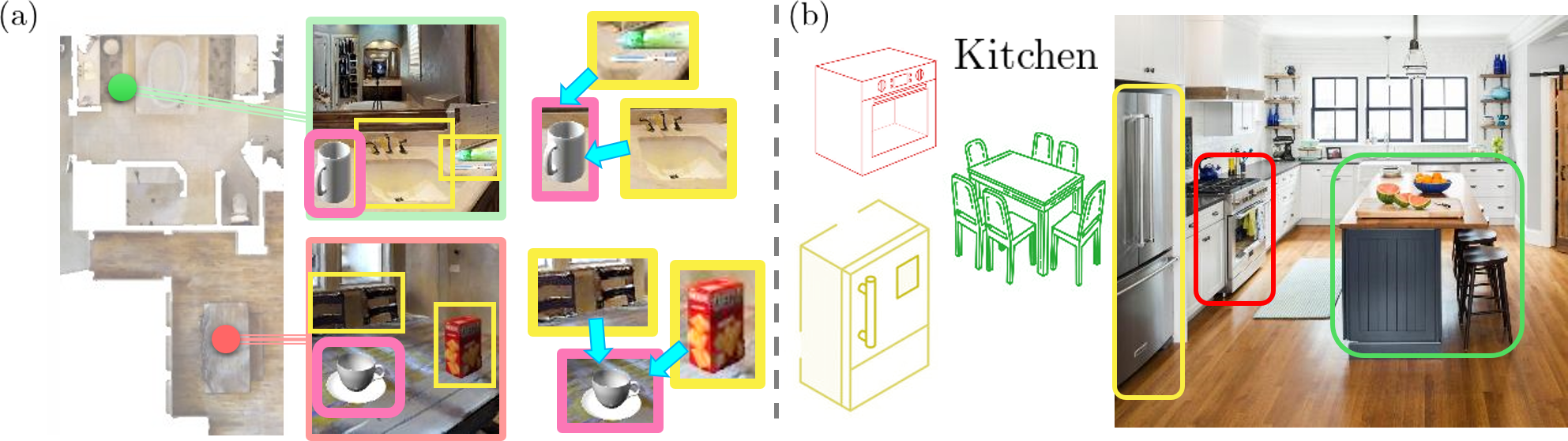
(a) The contextual representation, defining an object through neighboring objects, helps to eliminate the
ambiguity of similar but different objects.
For example, a cup in the kitchen can be perceived as one next to a chair and snack box, while a cup in the
bathroom can be shown as one that is near to a toothbrush and washstand.
(b) A place can be better described through objects. A kitchen, for instance, can be defined by the presence of
a refrigerator, oven, and dining table.
Graph builder: Semantic topological memory without pose sensor
The graph builder takes the observed RGB-D image to construct a
topological semantic graph. An image graph is constructed using a pretrained similarity encoder learns image similarity in an unsupervised
manner and is then used to determine whether or not the node is already in memory.
If the similarity is low, the observed image node is added to memory; otherwise, the image node is updated to
the most recent image representation.
When it turns out that the image node is new, it is connected to the previous image node, making the image
affinity matrix between the previous image node and the new node connected.
The object graph is formed simultaneously with the image graph.
If an observed object is not in the memory, the new object is added to the object graph memory.
Then, it is connected with the current image node.
To make objects in proximity connected in the graph memory, an affinity matrix for object nodes, which represents the connectivity between object nodes is calculated.
To calculate the object affinity matrix, image affinity matrix (\(A_{im}\)) and the image-object affinity matrix (\(A_{c}\)) are utilized.
Note that an image node is already connected to spatially neighboring image nodesand an object node is linked to the detected image nodes.
The object nodes connected to the adjacent image nodes are considered to be adjacent to the current object nodes,
\begin{align}
\begin{aligned}
A_{ob} = A_{c}^T (A_{im} + \text{I}) A_{c},
\end{aligned}
\end{align}
where I is an identity matrix, which connects the object nodes that share the same image node.
Cross graph mixer: Connecting two graphs for contextual info
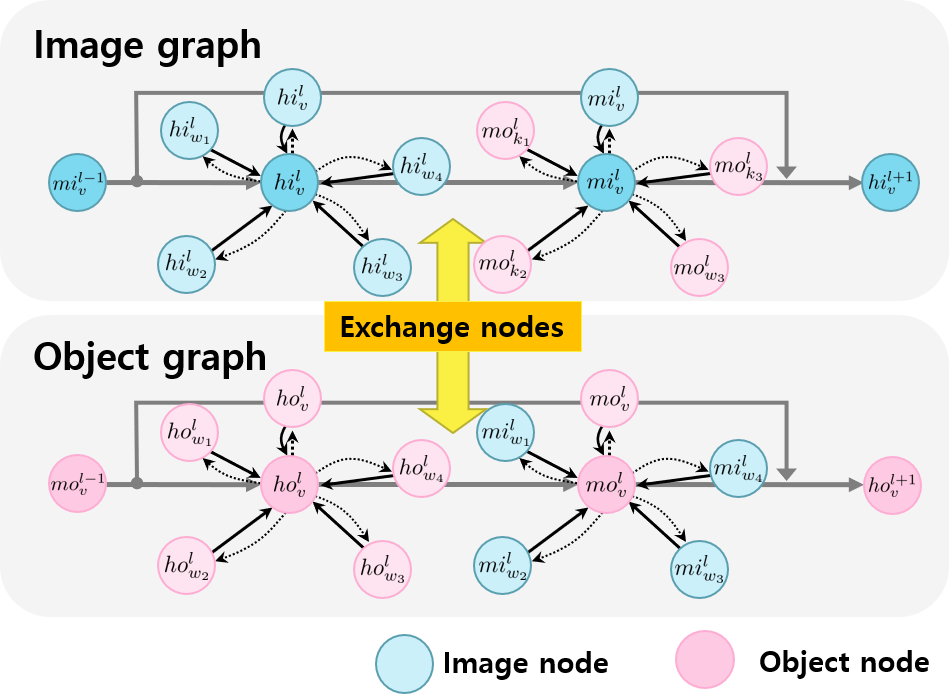
|
The cross graph mixer, a learnable message passing network
that exchanges object and image information, is used to make the memory contextual. The cross graph mixer is
developed from MPNNs to encode scene contexts by combining information from the image and object graphs.
The image and object nodes self-update to obtain contextual representations of nearby locations or objects.
Then, the self-update message function aggregates connected nodes with the message passing method.
The image-object update iterates to create semantic contextual node features.
It transfers messages from object nodes to image nodes and vice versa.
Memory decoder: Finding current and target nodes
TSGM is composed of visited image nodes and object nodes that have been observed.
For this, a memory decoder is used to discover the node
closest to the current state and goal among the memory.
Since this module utilizes attention, interpolation between visited nodes enables goal features to be extracted
from unexplored nodes.
The goal feature is given as a query when extracting a memory-conditioned goal feature and the current
observation feature is given as an input when selecting the memory-conditioned current feature.
Using the decoder module of the transformer network, current contextual feature and goal context feature are
collected.
Given the contextual feature for goal and current nodes, the action policy network finds an action to reach the
goal.
Oral Talk
Supplementary Video

|
Citation
@inproceedings{TSGM,
title={{Topological Semantic Graph Memory for Image Goal Navigation}}, author={Nuri Kim and Obin Kwon and Hwiyeon Yoo and Yunho Choi and Jeongho Park and Songhawi Oh}, year={2022}, booktitle={CoRL} } |
Acknowledgment
This work was supported by the Institute of Information & communications Technology Planning & Evaluation(IITP) grant funded by the Korea government(MSIT) (No. 2019-0-01309, Development of AI Technology for Guidance of a Mobile Robot to its Goal with Uncertain Maps in Indoor/Outdoor Environments)